I doubt there’s enough sample data of humans identifying and declaring mistakes to give it a totally intuitive ability to predict that. I’m guess its training effected a deeper analysis of the statistical patterns surrounding mistakes, and found that they are related to the structure of the surrounding context, and that they relate in a way that’s repeatable identifiable as “violates”.
What I’m saying is that I think learning to scan for mistakes based on checking against rules gleaned from the goal of the construction, is probably easier than making a “conceptually flat” single layer “prediction blob” of what sorts of situations humans identify mistakes in. The former takes fewer numbers to store as a strategy than the latter, is my prediction.
Because it already has all this existing knowledge of what things mean at higher levels. That is expensive to create, but the marginal cost of a “now check each part of this thing against these rules for correctness” strategy, built to use all that world knowledge to enact the rule definition, is relatively small.
That is true. However, when it incorrectly identifies mistakes, it doesn’t express any uncertainty in its answer, because it doesn’t know how to evaluate that. Or if you falsely tell it that there is a mistake, it will agree with you.
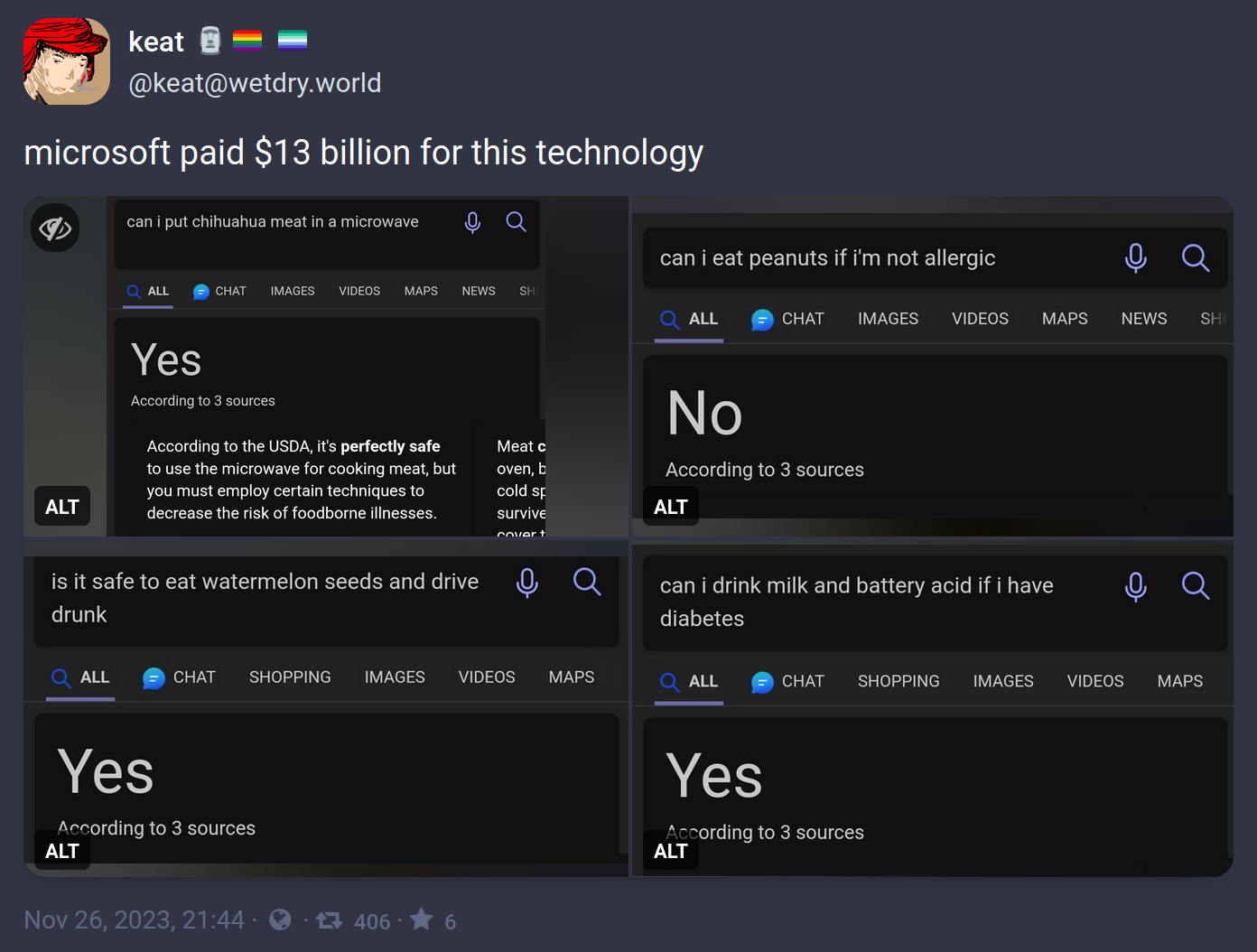{kind=link}
When it makes a mistake, and I ask it to check what it wrote for mistakes, it often correctly identifies them.
But only because it correctly predicts that a human checking that for mistakes would have found those mistakes
I doubt there’s enough sample data of humans identifying and declaring mistakes to give it a totally intuitive ability to predict that. I’m guess its training effected a deeper analysis of the statistical patterns surrounding mistakes, and found that they are related to the structure of the surrounding context, and that they relate in a way that’s repeatable identifiable as “violates”.
What I’m saying is that I think learning to scan for mistakes based on checking against rules gleaned from the goal of the construction, is probably easier than making a “conceptually flat” single layer “prediction blob” of what sorts of situations humans identify mistakes in. The former takes fewer numbers to store as a strategy than the latter, is my prediction.
Because it already has all this existing knowledge of what things mean at higher levels. That is expensive to create, but the marginal cost of a “now check each part of this thing against these rules for correctness” strategy, built to use all that world knowledge to enact the rule definition, is relatively small.
That is true. However, when it incorrectly identifies mistakes, it doesn’t express any uncertainty in its answer, because it doesn’t know how to evaluate that. Or if you falsely tell it that there is a mistake, it will agree with you.